
|
Research Characterizing the Composition of Metagenomic Samples from Next-Generation Sequencing 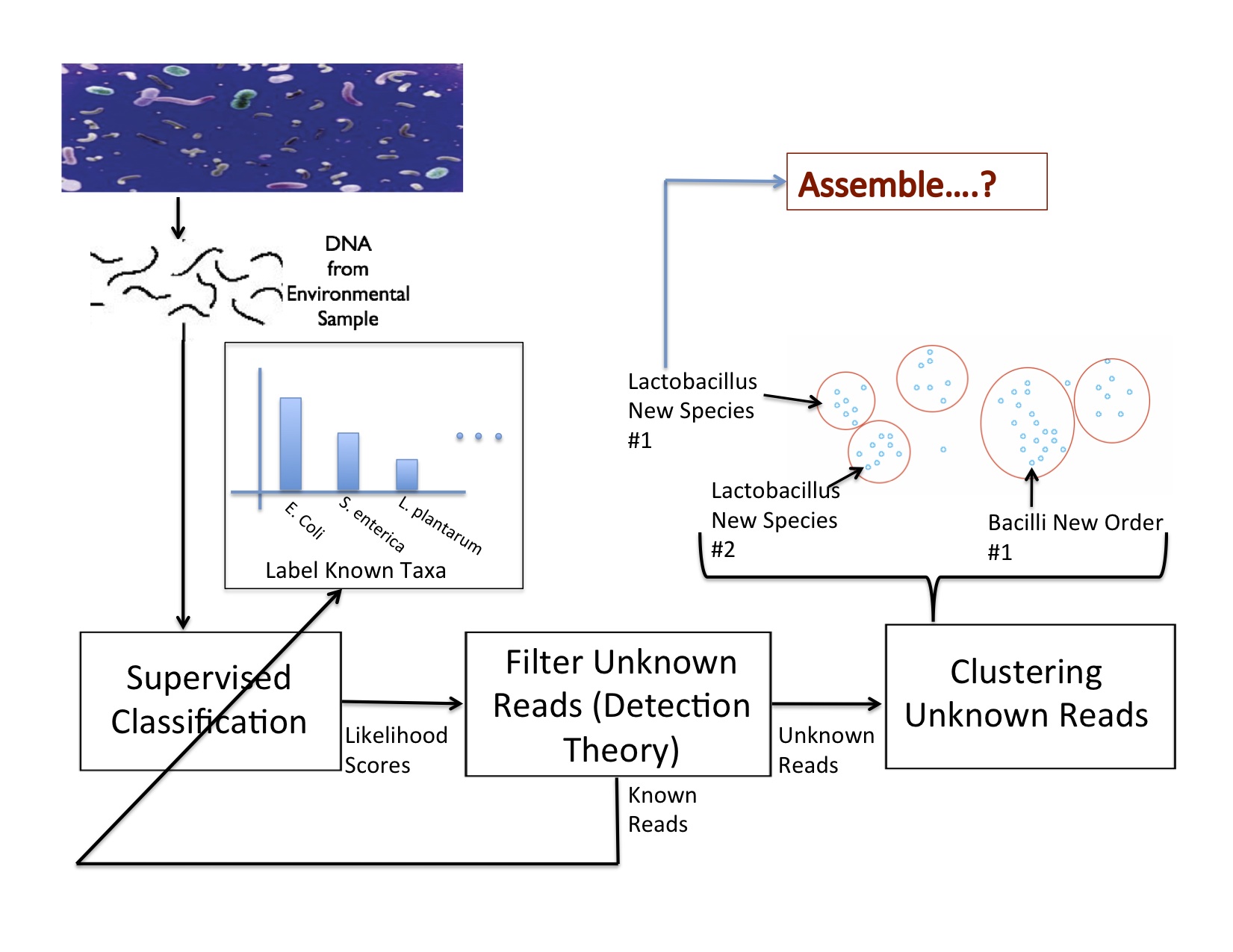 In characterizing communities of organisms from next-generation sequencing, it is important to accurately classify reads to organisms in known databases and then to identify and group novel organisms. Our solution has been to use a supervised classifier in order to maximize and leverage the little information we have in the databases, in order to then predict novel taxa. For the supervised classification problem, we have implemented several methods including support vector machines, cosine similarity and text mining methods, and the Naïve Bayes classifier (NBC) to try to derive an accurate solution. The most fast and accurate solution was the NBC, which we implemented on a website for medical and ecological use: http://nbc.ece.drexel.edu. We also show that detection theory can be used to distinguish between known and novel species and we are investigating ways to now cluster new organisms in an unsupervised manner.
In characterizing communities of organisms from next-generation sequencing, it is important to accurately classify reads to organisms in known databases and then to identify and group novel organisms. Our solution has been to use a supervised classifier in order to maximize and leverage the little information we have in the databases, in order to then predict novel taxa. For the supervised classification problem, we have implemented several methods including support vector machines, cosine similarity and text mining methods, and the Naïve Bayes classifier (NBC) to try to derive an accurate solution. The most fast and accurate solution was the NBC, which we implemented on a website for medical and ecological use: http://nbc.ece.drexel.edu. We also show that detection theory can be used to distinguish between known and novel species and we are investigating ways to now cluster new organisms in an unsupervised manner.Studying and Comparing the Functional Potential vs. Expression in Biological Communities 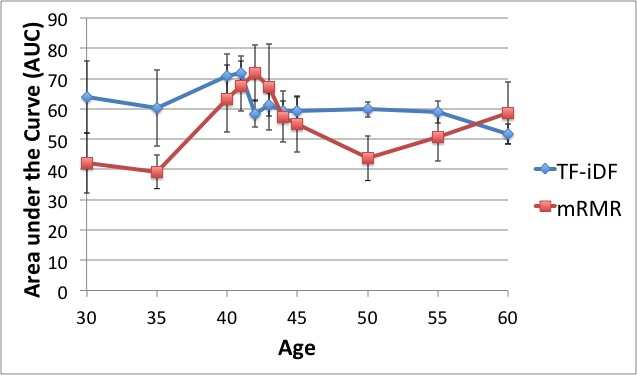 Using the Qin et al., 2010, dataset, we show that age 41/42 gives the best discrimination between two age groups. We believe this signifies a major shift in the microbiome sometime in the early 40's. While knowing the taxonomic composition of a sample is important since the community structure may be an indicator of the environment (including disease and other factors), understanding the sample's function and functional potential is even more useful. Inferring these functions will help us understand these systems and direct design of pharmaceuticals, remediation techniques, etc. to target components in these systems. The EESI Lab is investigating how gene ontology and protein domain relationships can predict environmental conditions. After annotating genes, we classify their function with databases such as Pfam (Protein family database), KEGG (Kyoto Encyclopedia of Genes and Genomes) Pathways database, clusters of orthologous genes (COG) that contain curated families and metabolic pathways of known genes. We are investigating how the occurrence of genes from specific protein families correlate to different human factors such as disease, age, and weight. For example, we have been able to predict if a person had inflammatory bowel disease (IBD) with an accuracy of over 75%. The most significant finding is that the early 40's yield the best ``cut-off" age for predicting whether a person was younger or older than that cut-off measured by the best area-under-the-curve (AUC) of the receiver operating characteristic curve for discriminating the two age groups. Environmental Community Comparison, Inferring system dynamics, and Modeling Environmental Gradients 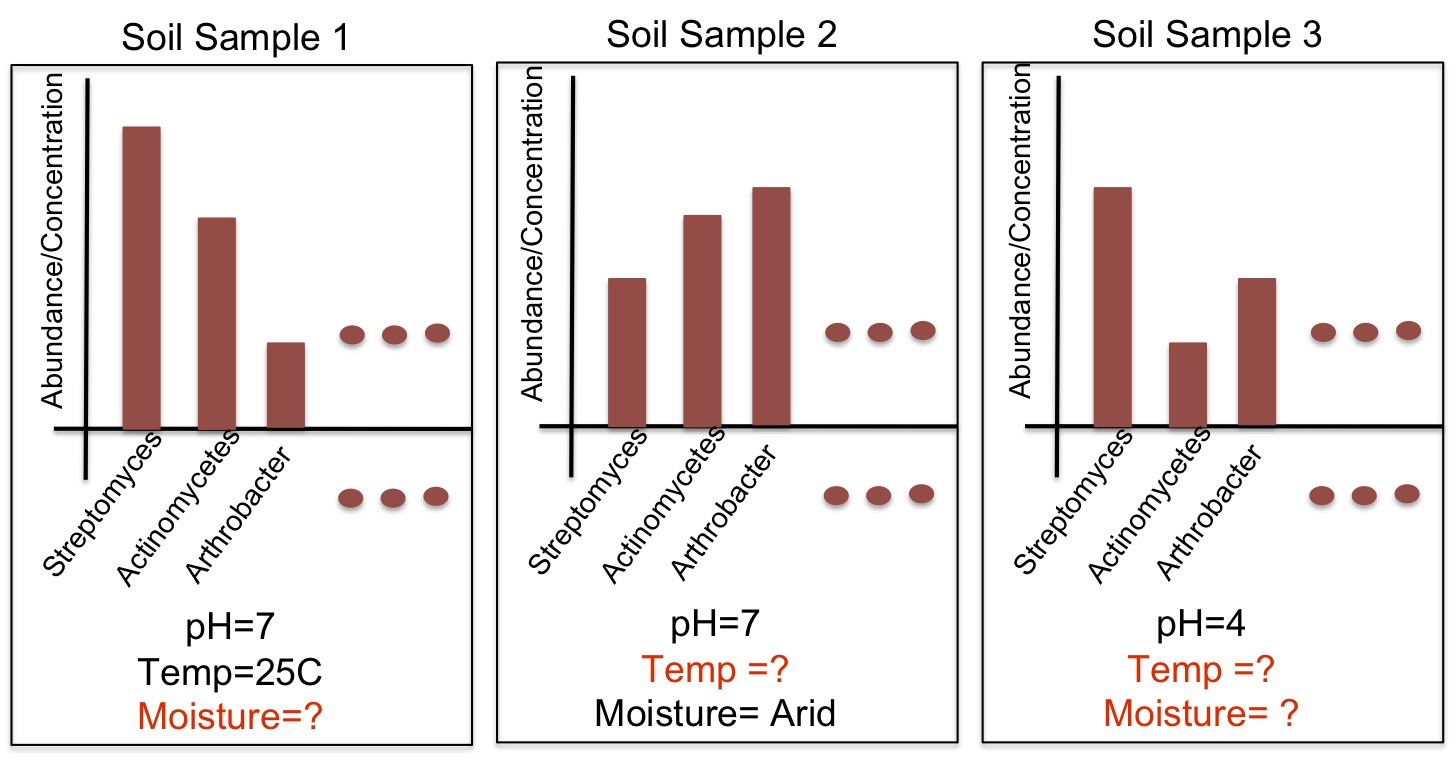 From community profiles of samples, we wish to infer missing labels Previously, investigators have shown that microbial populations are unique to individuals and that the microbes on a computer keyboard are correlated to the last person to touch it. This is a revolution in forensic analysis -- not only can our personal DNA be used in a potential investigation, but the microbes we harbor can reveal our identity. So we ask -- can microbes uniquely identify environments? If a certain trace of explosive chemical comes in contact with the soil, how do the microbial populations change with different levels of this chemical? Can we detect the chemical without measuring it directly but through changes in its microbial population? We aim to study microbial populations 16S rRNA gene and whole-genome (and transcriptome) shotgun sequencing to answer these questions. Suppose we have a database of complete taxonomic profiles, each of which has metadata associated it, such as pH, temperature, etc. We then collect and want to analyze more samples to obtain other taxonomic profiles, but for which the metadata might be incomplete (ex: the temperature is missing). This is commonplace in current databases, as very few standards have been implemented about which metadata to collect for which samples; the Genomic Standards Consortium is now leading the way to standardizing such procedures for biologists. So we ask -- is there a way to recover the missing parameters from the information available (in order to infer environmental factors from datasets that have been sequenced but ill-labeled)? We aim to answer these questions using function approximation and machine learning prediction. In conjunction with the Dept. of Mathematics and the Biostatistics department, we aim to solve this and other problems such as compressing genomic representation and solving issues with zeros in our data. Out of many problems that the EESI lab works on, this one has most promise to provide ecologists and clinicians with improved data that they may have lost by not recording enough metadata (about environmental conditions). |

